昨天写了三道代码题,还是有收获的
最后一题的题目要求是:
将一万以下的中文数字表达转为阿拉伯数字 比如 九千九百九十九 -> 9999
初看就是个模拟题,幸好前段时间在研究表达式模板语法,其实也是对一个特定的东西进行解析,一眼看过去其实不难的.然后就差点g了,幸好前面写的快~
开始准备3道题都用golang去写,前面2题都贼顺利(基本代码小于3行,只能说问题的解决方法完美存在于golang的原生库里,直接一把梭,我估计出题的人自己就是go批)
第三题后面发现有个大问题,单中文字符是啥类型啊,居然不是byte???,然后直接变得不会用golang了,直接宕机
但别急,急中生智的我拿出半年没用过的python,遂用python完成手撕,最后也是顺利通过了全部测试点:)
1 |
|
平常写代码最好还是不要开代码提示,不然手撕包写不出的,自己的编码能力也会大大退化,很难写出优雅的代码!
想起一个悲伤的故事
上次手撕字节的时候也是出现了一个很尴尬的点,就是忘记c语言的sizeof返回值是啥意思了…导致和面试官沟通的时候尴尬了很久~~
害,看来还是要多写代码,以及了解语言的本质,不能浮于表面,尤其要多查资料
最近在学最难的的语言rust,也是成功进入rust门!!,加入Rust神教
好了,看看昨天的问题如何解决
关于byte和rune
看如下代码:
1 | tar := "九千九百九十九" |
很显然第二种遍历是错误的
编译器会提示:无效运算: tar[k] == '九' (无法将常量 '九' 转换为类型 uint8)
原因在于’九’ 并不是我所认为的byte,而是rune,也是因为中文是unicode编码,因此是多字节,byte已经存储不了中文字符,因此采用rune来存储,不然早就超过了byte能表示的范围了,go的字符兼容性也是其一大特点,当时学的时候记得我看过这个知识点,好久不用又忘了_++_
可以看看打印出来的值
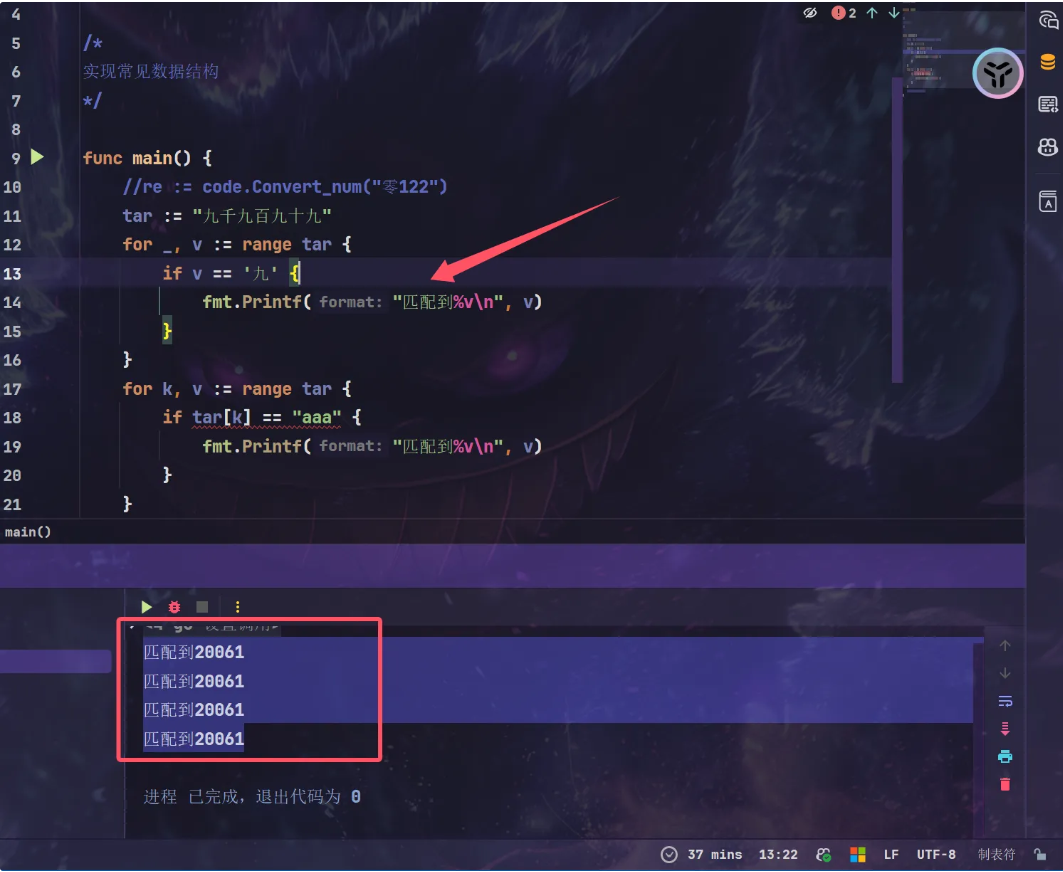
然后看看tar[k] 是个什么东东,如果我们 tar[k]==’a’ 那么是可以的,原因在于tar[k]取到的是取字符串的第 k 个 字节(byte),所以右边只能为单字节的byte(也就是 uint8) 而rune是int32
因为golang是强类型语言,自然在强制转换的时候就会出问题,编译器就能检查出错误
那么第一种的写法为什么又是正确的呢?
1 | tar := "九千九百九十九" |
这个range迭代出来的v又是个什么东东?看起来像是rune类型 因为range在遍历字符串时会自动按UTF-8解码为 rune(当为Unicode 字符时,一个byte表示不了,它会帮你完整的找出来)因此得到的就是准确的一个个字符
学到的:
Go 的range遍历字符串时,会自动按 UTF-8 解码每个字符为 rune,这是语言层面特性,不需要你手动处理字节。赶快回去翻开圣经:圣经YYDS!!!
整型 - Go语言圣经